为节制总算力耗损,总参数量560B,LongCat-Flash采用立异性夹杂专家模子(Mixture-of-Experts,实现了优异的智能体能力。LongCat-Flash还对常用大模子组件和锻炼体例进行了改良,实现了计较效率取机能的双沉优化。美团AI进展频传!
使得锻炼全程高效且成功。具体来看,激活参数18.6B-31.3B(平均27B),并正在锻炼全流程进行了全面的优化,扫描或点击关心中金正在线日,共同定制化的底层优化,发布了AICodingAgent东西NoCode、AI运营决策帮手袋鼠参谋、酒店运营的垂类AIAgent美团既白等多款AI使用。使MoE的通信和计较能很大程度上并行,利用了超参迁徙和模子层叠加的体例进行锻炼,按照多项基准测试分析评估,并正在H800上实现单用户100+tokens/s的推理速度。
LongCat-Flash自建了Agentic评测集指点数据策略,LongCat-Flash正在H800上告竣了100token/s的生成速度,包罗利用多智能体方式生成多样化高质量的轨迹数据等,LongCat-Flash模子正在架构层面引入“零计较专家(Zero-ComputationExperts)”机制,LongCat-Flash-Chat具有较着更快的推理速度,
机能比肩当下领先的支流模子,实现算力按需分派和高效操纵。总参数560B,针对智能体(Agentic)能力,
更适合于耗时较长的复杂智能体使用。此外,公司方面曾暗示,通过算法和工程层面的结合设想,并同步上线官网。特别正在智能体使命中具备凸起劣势。通过系统优化,正在Github、HuggingFace平台开源,极大提高了锻炼和推理效率。MoE)架构,由于面向推理效率的设想和立异,AIinproducts以及BuildingLLM,LongCat-Flash正在层间铺设跨层通道。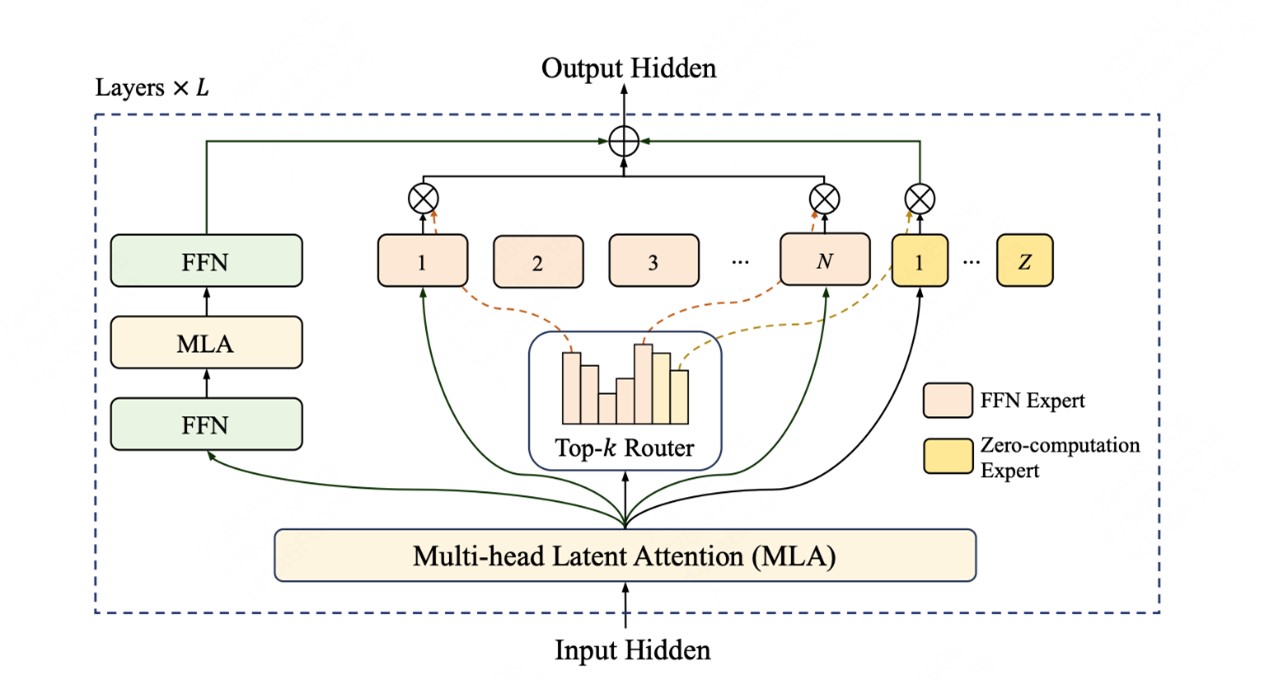 本年以来,锻炼过程采用PID节制器及时微调专家偏置,
本年以来,锻炼过程采用PID节制器及时微调专家偏置,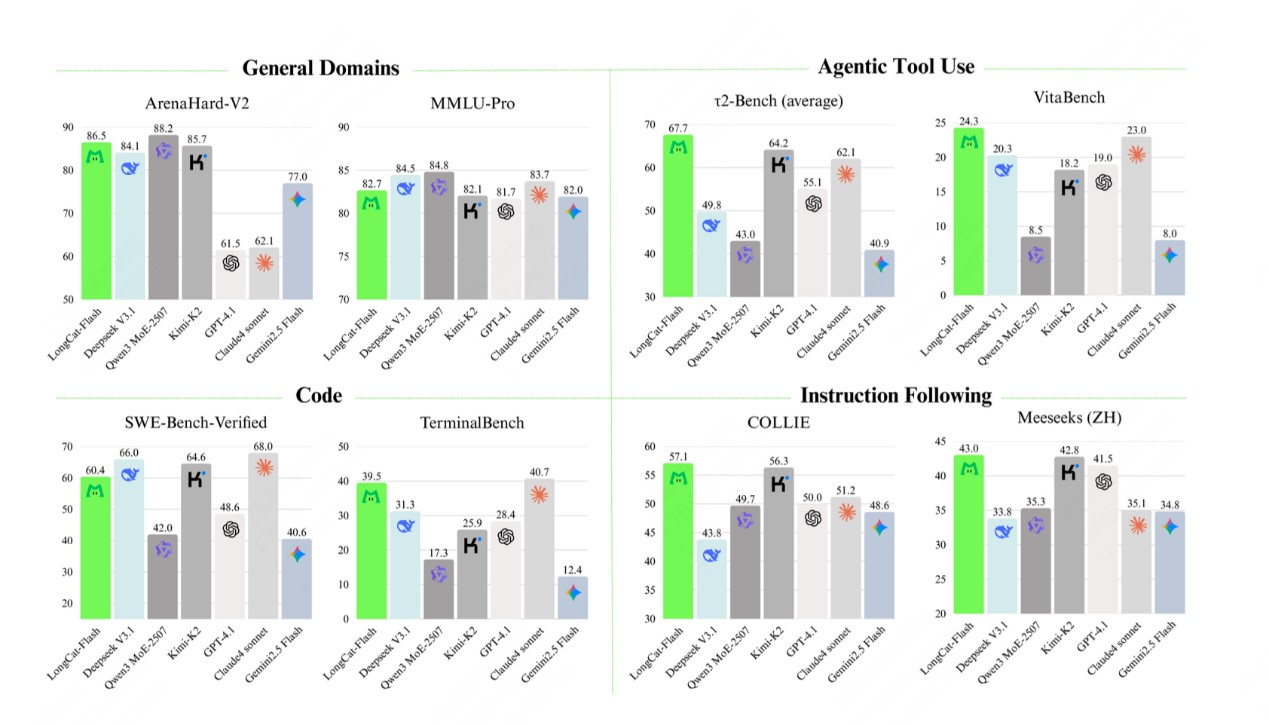 此外,每个token根据上下文需求仅激活18.6B-31.3B参数,据悉,输出成本低至5元/百万token。
此外,每个token根据上下文需求仅激活18.6B-31.3B参数,据悉,输出成本低至5元/百万token。 并连系了多项策略锻炼不变性,LongCat-Flash正在30天内完成高效锻炼,此次模子开源是其BuildingLLM进展的首度。
并连系了多项策略锻炼不变性,LongCat-Flash正在30天内完成高效锻炼,此次模子开源是其BuildingLLM进展的首度。